
Як насправді працює рейтинг у пошуку Google з технічного боку
У березні 2024 року стався виток інформації Google, який ледь не вперше дав розуміння, як насправді працює ранжування і як формується видача SERP. SEO-спеціаліст Promodo Олександр Ковальчук підготував детальний матеріал з розбором конкретних алгоритмів і модулів, які використовує Google для скринінгу, оцінювання та ранжування сторінок. У тексті зібрана найактуальніша інформація та пояснення, які допоможуть у роботі з SEO.

Кожен, хто знайомий з інтернет-послугами, хоч раз користувався пошуковою системою Google. Для звичайного користувача це поле для введення потрібного питання, після чого відбувається «магія» і ви отримуєте різні відповіді на ваш запит.
Натомість власники сайтів, маркетологи та SEO-спеціалісти знають, що видача SERP формується не магічним чином, а завдяки певним алгоритмам. Неписане правило звучить так: що кращий сайт, тим вищу він матиме позицію у пошуку.
У новому матеріалі Promodo розберемося, як працює пошукова система, що відбувається на різних етапах оцінки сайту та яких правил роботи з SEO потрібно дотримуватися, щоб залишатися у топі видачі.
Як пошукова система оцінює вебсторінки
Для оцінювання вебсторінок та заповнення індексу пошукової системи, Google використовує власний автоматичний інструмент — вебсканер Googlebot. Він працює за наступним алгоритмом: Сканування → Індексування → Ранжування.
На перший погляд, виглядає просто, але проблеми можуть розпочатися ще на етапі «сканування».

Процес сканування звичайного сайту зі статичним HTML немає ніяких особливостей. Googlebot приходить на сайт і бачить лише базовий код сторінки — HTML. Якщо весь контент вже є в цьому коді, то він просто сканує сторінку і визначає потребу у рендерингу. Але такий сценарій не спрацює для сайтів, які використовують скрипти.
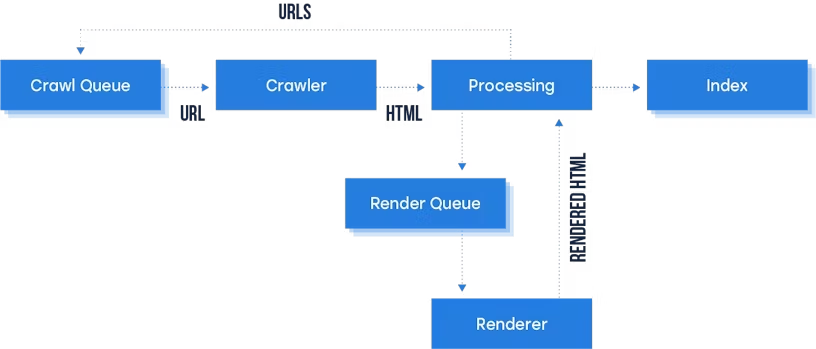
Якщо контент на сторінці генерується динамічно через JavaScript, то після того, як Googlebot отримує початковий HTML, сторінка потрапляє в чергу для рендерингу (Render Queue). Рендерер працює подібно до браузера, відтворюючи сторінку, як це робить реальний користувач у браузері. Після виконання всіх необхідних скриптів та рендерингу сторінки, отримується відрендерений HTML. Тепер Googlebot має доступ до повного контенту на сторінці: тексту, зображень, форм, таблиць і всього іншого, що було додано за допомогою JavaScript.
Googlebot перевіряє, чи є отриманий вміст HTML-сторінкою: Якщо ні (наприклад, це PDF або інший тип файлу), Googlebot обробляє файл як є, без додаткового рендерингу (пропускає етап рендерингу).
Що важливо врахувати на етапі сканування
- Швидкість завантаження сайту. Google рекомендує, щоб час відповіді сервера був мінімальним і не перевищував 2-3 секунд.
- Неправильні налаштування у файлі robots.txt. Інакше ваш сайт ніколи не зацікавить Googlebot.
- Щоб весь контент був доступний для сканування. Досить часто проблема є прихованою, коли ви використовуєте сторонні ресурси, але не відкриваєте їх для доступу Googlebot.
- Сайти на JavaScript мають свої складнощі. При використанні JavaScript сторінка може спочатку завантажитися з порожнім або неповним вмістом — це може призвести до певних проблем для Googlebot і інших пошукових систем під час спроби сканування та індексації контенту.
Етапи роботи Google-пошуку
Кожен етап в роботі пошукової системи надзвичайно важливий, і може бути для вас як перевагою серед конкурентів, так і суттєвою проблемою у ранжуванні сайту.
Намалювати коректну картину структури пошукової системи важко, але ми наведемо приклад роботи Маріо Фішера.
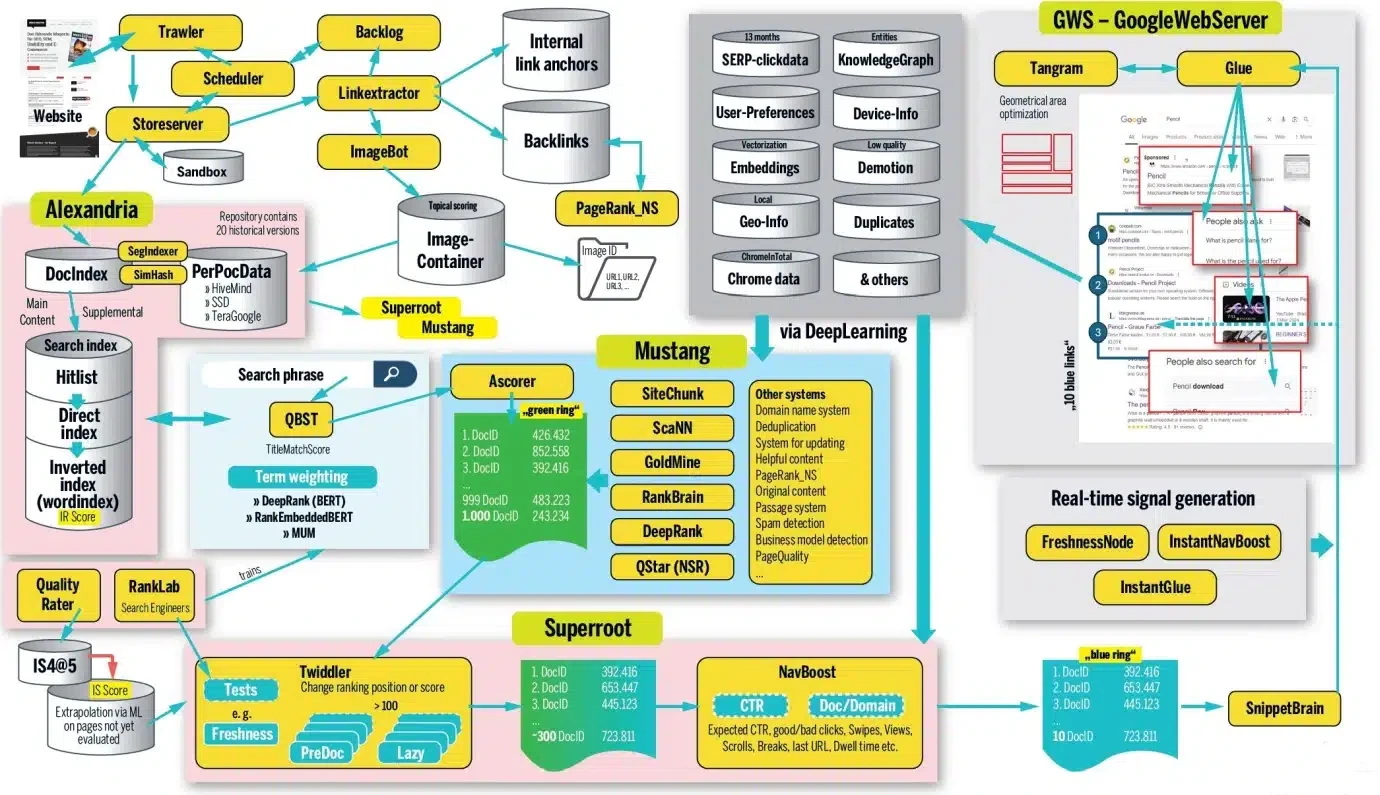
Ця схема побудована на основі витоку інформації, який стався у березні 2024 року під час антимонопольних слухань проти компанії Google. Витік виявив понад 14 000 потенційних функцій ранжирування, що практично вперше надає можливість справді зазирнути всередину системи пошуку Google.
Під час огляду, ми досить часто будемо звертатися до конкретних алгоритмів і модулів, тому пропонуємо одразу ознайомитися з відповідними патентами:
| Algorithm | Patent Number | Patent Link |
| DocIndex | US20080119159A1 | US20080119159A1 |
| SegIndexer | US20150175361A1 | US20150175361A1 |
| SimHash | US7657674B1 | US7657674B1 |
| PerDocData | US20080119159A1 | US20080119159A1 |
| Hitlist | US20090235859A1 | US20090235859A1 |
| Direct Index | US20080119159A1 | US20080119159A1 |
| Inverted Index | US6546237B1 | US6546237B1 |
| QBST | US20160244375A1 | US20160244375A1 |
| Term Weighting | US7032051B1 | US7032051B1 |
| Mustang | US20090014956A1 | US20090014956A1 |
| SiteChunk | US20090014956A1 | US20090014956A1 |
| ScanMin | US20080259677A1 | US20080259677A1 |
| GoldMine | US20090195317A1 | US20090195317A1 |
| RankBrain | US20150062652A1 | US20150062652A1 |
| DeepRank | US20160292055A1 | US20160292055A1 |
| QStar (NSR) | US20080259677A1 | US20080259677A1 |
| GWS | US7020970B1 | US7020970B1 |
| Tangram | US20110269188A1 | US20110269188A1 |
| InstantNavBoost | US20130143324A1 | US20130143324A1 |
| InstantGlue | US20130274445A1 | US20130274445A1 |
| FreshnessNode | US20070139203A1 | US20070139203A1 |
| Quality Rater | US20070083625A1 | US20070083625A1 |
| SnippetBrain | US20120174542A1 | US20120174542A1 |
| Superroot | US20090159259A1 | US20090159259A1 |
Збір та збереження даних у сховищах (Alexandria)
Розпочнемо з того, що всі проскановані сторінки переходять до наступного етапу — індексації та зберігаються в базі Alexandria.
Alexandria — це сховище, яке зберігає різні версії даних. Система індексування Google під назвою «Александрія» призначає унікальний DocID кожному вмісту.
Робота з базою даних працює за допомогою декількох алгоритмів:
- DocIndex відповідає за створення індексу документів, що дозволяє швидко знаходити потрібні файли в системі зберігання даних.
- SegIndexer відповідає за процес сегментації документів — розподіляємо їх на окремі частини або сегменти, які можуть бути індексовані та збережені окремо.
- SimHash — це метод для виявлення дублікатів. Алгоритм генерує хеш (спеціальний закодований номер) для кожного документа, що дозволяє порівнювати його з іншими файлами на наявність схожих або ідентичних частин.
- PerDocData — це система для зберігання даних для кожного документа з його специфічними метаданими, такими як інформація про автора, час створення, зміст, ключові слова тощо. Ця інформація та сигнали динамічно зберігаються в репозиторії ( PerDocData ).
Важливо: Google розрізняє URL-адресу та документ. Документ може складатися з кількох URL-адрес зі схожим вмістом, зокрема різними мовами, якщо вони належним чином позначені. Тут також сортуються URL-адреси з інших доменів. Усі сигнали з цих URL-адрес застосовуються через загальний DocID.
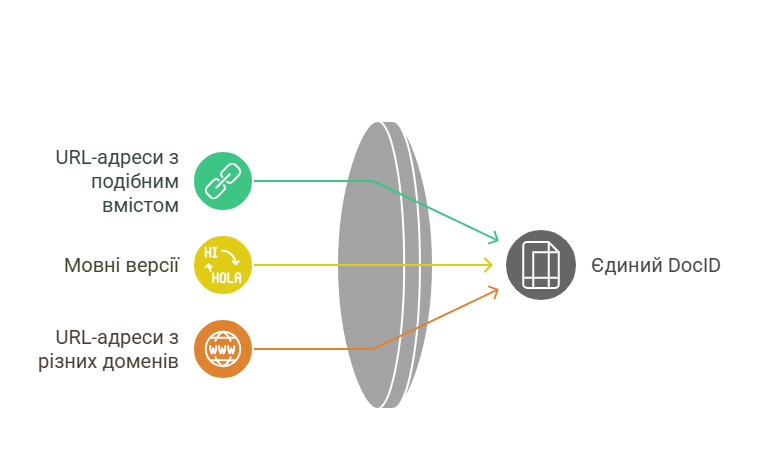
Коли кожному документу присвоюється власний ідентифікатор, водночас проходить процес оцінки слів, які виявлені на сторінці. Формується пошуковий індекс за релевантними ключовими фразами.
Саме на цьому етапі початково аналізується релевантність вашого контенту у документі:
- кількість входжень ключових слів;
- входження ключових фраз у метадані;
- формування заголовків;
- тощо.
У підсумку, для кожного ідентифікатора DocID присвоюється оцінка IR (information retrieval), яка є алгоритмічно обчислювана. Загалом ця оцінка і вирішує, чи буде ваша сторінка у першій десятці, чи взагалі сторінка буде ранжуватися за певною ключовою фразою.
А далі відбувається те, що може надовго викинути вашу сторінку з топу. І причина ховається в тому, що Google намагається економити свої ресурси. Він переміщує важливі документи в так званий HiveMind, тобто основну пам’ять і використовує як швидкі SSD, так і звичайні жорсткі диски (іменовані TeraGoogle) для тривалого зберігання інформації, яка не потребує швидкого доступу.
Дослідники зауважують, що посилання, включно зі зворотними посиланнями, які зберігаються в HiveMind, мають значно більшу вагу.
Багато систем звертаються до PerDocData пізніше, коли справа доходить до точного налаштування релевантності. Там зберігаються останні 20 версій документа (через CrawlerChangerateURLHistory).
Усе це наштовхує на логічні висновки:
- Аналіз контексту сторінки (документу) розпочинається з самого початку.
- Google може з легкістю вичислити ваші маніпуляції, зберігаючи до 20 останніх версій вашого документа.
Наприклад, існувала практика оновлення статей блогу лише через оновлення дати — вважалося, що це достатній сигнал для покращення ранжування. А насправді алгоритми системи пошуку використовують декілька перевірок: BylineDate (дата у вихідному коді), syntaticDate (витягнута дата з URL-адреси та/або заголовка) і semanticDate (взята з доступного для читання вмісту). І це дозволяє досить непогано визначити, чи справді контент було оновлено. Сюди додайте також порівняння з іншими 19 версіями документа і як результат — це сприяє пониженню рейтингу. - Збереження 20 копій документа наштовхує на думку, що часто для покращення ранжування недостатньо зміни якогось одного фактора. Якщо ви хочете повністю змінити вміст або тему документа, теоретично, вам потрібно створити 20 проміжних версій, щоб замінити старі сигнали вмісту.
Обробка в різних системах індексації
Коли сторінка потрапляє до сховища Alexandria, вона вже має унікальний ідентифікатор — DocID — і зберігається разом з усіма пов’язаними сигналами, метаданими та версіями контенту. Тому розглянемо детальніше, як відбувається процес пошуку потрібного документу з ідентифікатором (DocID) за відповідним запитом.
Після того, як документ зберігається в базі та отримує унікальний DocID, пошукова система має швидко знайти його серед мільярдів інших, коли хтось вводить запит. Для цього використовується кілька рівнів пошуку — від найшвидшого до найточнішого.
1. Hitlist — швидкий старт
Спочатку пошукова система звертається до так званого Hitlist — це список документів, які вже раніше були визначені як релевантні для певних запитів. Такий список дозволяє дуже швидко отримати результати, бо система просто «дістає» готові відповіді.
2. Direct Index — якщо потрібно точніше
Якщо Hitlist не дає достатньо релевантних результатів, підключається Direct Index — індекс, який напряму пов’язує слова з документами, в яких вони зустрічаються. Це вже глибший рівень аналізу, який дозволяє знайти нові або менш очевидні відповіді.
3. Inverted Index — найпотужніший інструмент
Для ще складніших запитів використовується Inverted Index. Замість того, щоб зберігати документи з їх вмістом, він зберігає слова з прив’язкою до всіх документів, де вони є. Тому Inverted Index добре підходить для складних запитів та дозволяє економити ресурси, оскільки працює з меншим обсягом даних.
| Hitlist | Швидкий доступ до «важливих» сторінок.Пришвидшення відповіді на пошукові запити. |
| Direct Index | Прямий індекс як засіб зменшення часу доступу. |
| Inverted Index (wordindex) | Механізм зворотного індексу: пошук за ключовими словами.Важливість для ефективного зіставлення запит–контент. |
Це ще раз підтверджує гіпотезу, що при формуванні контенту, важливо не лише додавати ключові фрази, а й формувати певну структуру тексту та відповідати запиту користувача.
Аналіз запиту
Коли користувач вводить пошуковий запит, підключаються алгоритми, які
- оцінюють та аналізують запит для розуміння контексту;
- QBST оцінює релевантність — наскільки документи відповідають запиту користувача;
- звужують терміни для точного ранжування.
QBST (Query-based Scoring Tool) — це внутрішній інструмент Google, який оцінює релевантність документів стосовно пошукового запиту. Його мета обрати найбільш релевантний документ. Процес зважування термінів досить складний і включає такі системи, як RankBrain, DeepRank (раніше BERT) і RankEmbeddedBERT.
Розглянемо детальніше, що саме роблять алгоритми та чим відрізняється їх робота на різних етапах.
| Алгоритм | Основна функція | Особливість |
| Term Weighting | Визначення важливості термінів | Обчислює, які слова в запиті або документі є ключовими для релевантності |
| RankBrain | Векторизація запитів | Обробляє нові/незрозумілі запити |
| DeepRank (BERT) | Розуміння контексту | Оцінює відповідність сторінки запиту |
| RankEmbeddedBERT | Векторна семантика | Глибока релевантність на основі сенсу |
«Банальне» використання ключових фраз у тексті вже є недостатнім для оцінки вашого контенту не лише як корисного, а й релевантного до поставленого запиту користувачем. Це стає зрозумілим зі складності оцінки алгоритмами, залучення штучного інтелекту та направленість на визначення прихованого наміру користувача.
Ще один елемент для аналізу, який Google використовує у роботі із запитами, це Knowledge Graph.
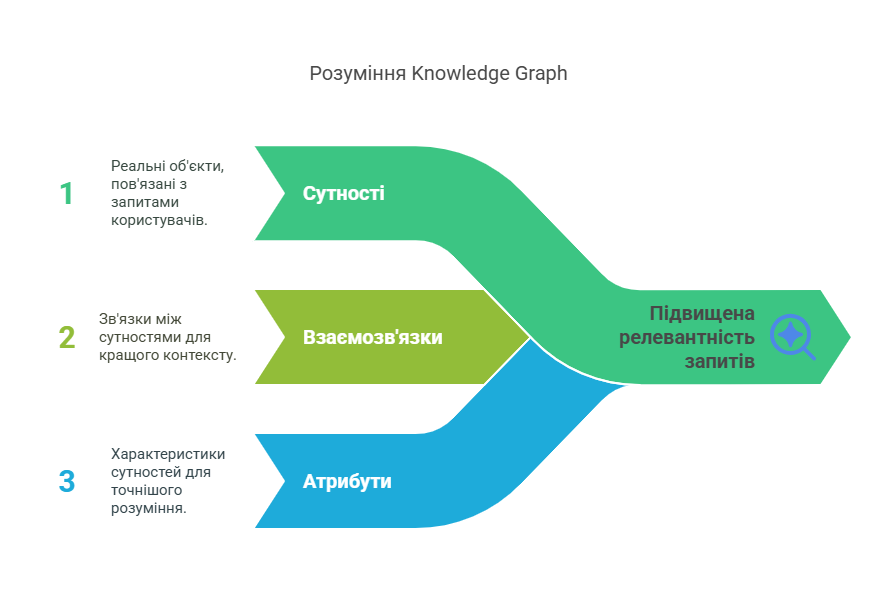
Якщо говорити простою мовою — це умовний словник, де запити пов’язуються зі справжніми сутностями, а не просто словами. Схематично це виглядає так:
Після оцінки запиту, він передається у систему оцінки рейтингу Mustang, де розпочинається процес підбору релевантних документів.
Модулі ранжування
Це етап, коли пошукова система вже знає, які сторінки можуть відповідати на запит, і тепер вона вирішує: які з них найкращі? І в якому порядку їх показувати?
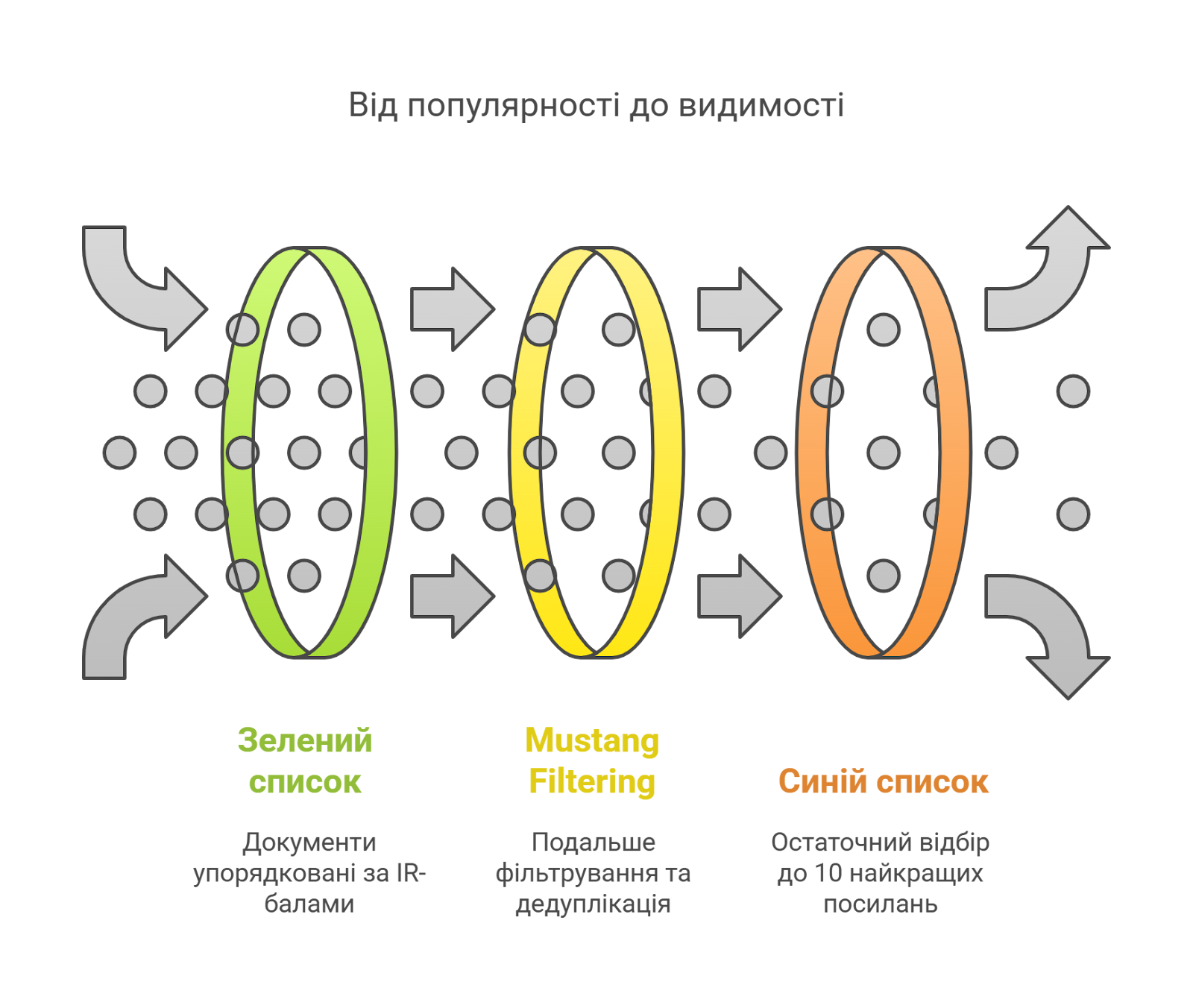
Запит передається Ascorer для подальшої обробки — він отримує 1000 найпопулярніших DocID для заданого запиту (ключової фрази) з Inverted Index, упорядкованого за IR-балом. Згідно з внутрішніми документами, цей список іменується «зеленим кільцем».
Далі в системі модуля Mustang відбувається фільтрація результатів для точнішого відбору сторінок:
- Видаляються дублі: якщо кілька сторінок мають майже однаковий вміст, за допомогою алгоритму SimHash визначається найоригінальніша.
- Аналізуються уривки: модуль перевіряє, наскільки добре фрагменти сторінки (наприклад, заголовки чи перші абзаци) підходять до запиту.
- Відбувається пошук оригінальний і корисний контенту: система віддає перевагу сторінкам з унікальною та цінною інформацією, а не просто зібраним з інтернету текстом.
Цей результат досягається завдяки тому, що система Mustang об’єднує моделі для створення єдиної логіки пошуку: визначає, які підмоделі та сигнали активувати для кожного запиту. Можна сказати, це «диригент» пошукового процесу. Під час її роботи використовуються такі «низькорівневі» алгоритми: ScanMin (ScaNN), SiteChunk, GoldMine, QStar, PageRank.
- ScanMin (ScaNN) — алгоритм векторного пошуку, який дозволяє швидко знаходити найбільш схожі документи за векторною близькістю.
- SiteChunk — розбиває сайт або сторінку на логічні «частини» (chunks), щоб краще аналізувати контент і покращити розуміння структури документа.
- GoldMine — внутрішній інструмент, який відповідає за витягування структурованих даних з неструктурованого тексту.
- QStar (NSR — Neural Semantic Retrieval) використовує глибоке семантичне розуміння запиту й документа для нейронного ранжування результатів, працює на базі векторних представлень.
- PageRank — класична основа ранжування на основі авторитетності.
За уточнення результатів відповідає система Superroot, яка дає змогу провести переранжування, виконуючи точну роботу зі скорочення «зеленого кільця» (1000 DocID) до «синього кільця» лише з 10 результатами.
Важливою частиною системи Superroot є модуль Navboost. Він відповідає за те, щоб Google міг легко оцінити пошукову поведінку, включно з пошуком, кліками, повторними пошуками та кліками — безпосередньо в результатах пошуку. Поговоримо про модуль Navboost трохи згодом.
Формування видачі
Настав час сформувати результати видачі для користувача. Для цього GWS, який отримує результати з попередніх модулів обробки запиту, збирає остаточну сторінку для користувача.
GWS (Google Web Server) — це сервер, який відповідає за обробку фінального запиту користувача та вивід результатів пошуку в браузері.
Разом з цим ще 2 модулі працюють паралельно, для формування кінцевого результату SERP:
- Tangram — це шаблонний та логічний модуль, який відповідає за структурування SERP. За задумом він динамічно адаптує блоки, щоб SERP був найбільш корисним.
- Glue — це модуль, який інтегрує всі типи результатів. Завдяки Glue результат «оживає»: він має фавікон, зірочки рейтингу, ціни, навігацію — все, що виводиться у SERP поза звичайним посиланням.
Сигнали реального часу
Коли здається, що вже всі етапи пройдено, усі аналізи зроблено, а висновки отримано — Google продовжує доопрацьовувати свою видачу. Навіть коли система Superroot сформувала результат у вигляді «синього кільця» (10 документів), Google продовжує відслідковувати, як користувач реагує на отриманий результат. Розглянемо детальніше, які алгоритми це роблять:
- FreshnessNode — модуль, що оцінює актуальність документа або сторінки в момент запиту.
- InstantNavBoost — модуль, що слідкує за тим, чи «задоволений» користувач результатом, чи знову повертається у видачу. InstantNavBoost враховується в мікроранжуванні — може змінити позицію документа в конкретній сесії чи для подібних запитів.
- InstantGlue — доповнення до модуля Glue, яке в реальному часі змінює структуру SERP, залежно від запиту та контексту.
Тому видача може змінюватися буквально в реальному часі, залежно від попиту, поведінки та контексту. І найпевніше саме ця частина найбільше впливає на те, як ранжується новий контент та втрачає свої позиції застарілий.
Тестування
Водночас з тим, як користувачу віддається результат з системи Mustang, чи оновлений результат після Superroot, відбувається процес тестування.
Для цього Google використовує Twiddler — платформу для експериментів і «тонкого підкручування» результатів, яка дозволяє запускати A/B тести в SERP у реальному часі. Різні документи вказують на те, що використовується кілька сотень систем Twiddler.
Ви не можете вплинути на те, як Twiddler змінює порядок ваших результатів, але розуміння його механізмів може допомогти вам інтерпретувати коливання рейтингу або «незрозумілі рейтинги». Важливо регулярно переглядати SERP і зазначати типи результатів.
Система Twiddlers формує варіанти видачі для тестування, а додатковий модуль IS4@5 проводить розгортання на інфраструктуру ранжування в реальному часі, забезпечуючи швидке тестування даних варіантів.
Google формує результати пошуку на основі тисяч сигналів. Через постійні тести у SearchLab та систему Twiddler навіть зворотні посилання можуть втратити вагу. Тобто, якщо змінюється поведінка користувачів — ваш сайт може втратити позиції, навіть якщо ви нічого не змінювали.
Оцінка якості (Quality Rater)
Для того, щоб кожен модуль та система працювали успішно, Google постійно оцінює їх результати та «тренує» свою автоматичну систему оцінки. Для цього компанія використовує кілька тисяч оцінювачів якості по всьому світу і заявляє, що їхні оцінки безпосередньо не впливають на рейтинг.
Як працює система оцінювання якості сторінок (Quality Rater):
- Спеціальні оцінювачі перевіряють сайти та відповідають на запитання, які допомагають оцінити якість контенту.
- Їхні відповіді використовуються для навчання алгоритмів — щоб система розуміла, чим хороший сайт відрізняється від поганого.
- Частині перевірених сторінок присвоюється оцінка IS (Information Satisfaction) — наскільки добре сторінка відповідає на запит. Цю оцінку потім поширюють на схожі сторінки — щоб автоматично ранжувати їх без ручної перевірки.
- Якщо система не може знайти схожі сторінки, вона знову звертається до оцінювачів.
- Що більше оцінювачі перевіряють вручну, тим більше сайтів надалі система може оцінювати сама.
З суттєвим покращенням моделей машинного навчання, найпевніше, роль оцінювачів буде змінюватися, але оцінка живого користувача все ще залишатиметься важливою. Тому час згадати інструкцію для асесорів, відповідно до якої, оцінювачі й проводять аналіз сторінок. Чим краще ви розумієте критерії — тим ближче ви до топових позицій.
Висновок
Ваш сайт може зіткнутися з проблемами як на етапі виявлення сайту пошуковою системою, так і на етапі його оцінки та подальшого ранжування. Адже Google використовує для своєї екосистеми складний підхід, який постійно еволюціонує.
Краще розуміння алгоритмів та процесів, які відбуваються під час оцінювання вашого сайту, дозволяє будувати більш життєздатні гіпотези щодо необхідних впроваджень.
Автор: Олександр Ковальчук, SEO-спеціаліст Promodo
Як насправді працює рейтинг у пошуку Google з технічного боку
У березні 2024 року стався виток інформації Google, який ледь не вперше дав розуміння, як насправді працює ранжування і як формується видача SERP. SEO-спеціаліст Promodo Олександр Ковальчук підготував детальний матеріал з розбором конкретних алгоритмів і модулів, які використовує Google для скринінгу, оцінювання та ранжування сторінок. У тексті зібрана найактуальніша інформація та пояснення, які допоможуть у роботі з SEO.
Кожен, хто знайомий з інтернет-послугами, хоч раз користувався пошуковою системою Google. Для звичайного користувача це поле для введення потрібного питання, після чого відбувається «магія» і ви отримуєте різні відповіді на ваш запит.
Натомість власники сайтів, маркетологи та SEO-спеціалісти знають, що видача SERP формується не магічним чином, а завдяки певним алгоритмам. Неписане правило звучить так: що кращий сайт, тим вищу він матиме позицію у пошуку.
У новому матеріалі Promodo розберемося, як працює пошукова система, що відбувається на різних етапах оцінки сайту та яких правил роботи з SEO потрібно дотримуватися, щоб залишатися у топі видачі.
Як пошукова система оцінює вебсторінки
Для оцінювання вебсторінок та заповнення індексу пошукової системи, Google використовує власний автоматичний інструмент — вебсканер Googlebot. Він працює за наступним алгоритмом: Сканування → Індексування → Ранжування.
На перший погляд, виглядає просто, але проблеми можуть розпочатися ще на етапі «сканування».
Процес сканування звичайного сайту зі статичним HTML немає ніяких особливостей. Googlebot приходить на сайт і бачить лише базовий код сторінки — HTML. Якщо весь контент вже є в цьому коді, то він просто сканує сторінку і визначає потребу у рендерингу. Але такий сценарій не спрацює для сайтів, які використовують скрипти.
Якщо контент на сторінці генерується динамічно через JavaScript, то після того, як Googlebot отримує початковий HTML, сторінка потрапляє в чергу для рендерингу (Render Queue). Рендерер працює подібно до браузера, відтворюючи сторінку, як це робить реальний користувач у браузері. Після виконання всіх необхідних скриптів та рендерингу сторінки, отримується відрендерений HTML. Тепер Googlebot має доступ до повного контенту на сторінці: тексту, зображень, форм, таблиць і всього іншого, що було додано за допомогою JavaScript.
Googlebot перевіряє, чи є отриманий вміст HTML-сторінкою: Якщо ні (наприклад, це PDF або інший тип файлу), Googlebot обробляє файл як є, без додаткового рендерингу (пропускає етап рендерингу).
Що важливо врахувати на етапі сканування
- Швидкість завантаження сайту. Google рекомендує, щоб час відповіді сервера був мінімальним і не перевищував 2-3 секунд.
- Неправильні налаштування у файлі robots.txt. Інакше ваш сайт ніколи не зацікавить Googlebot.
- Щоб весь контент був доступний для сканування. Досить часто проблема є прихованою, коли ви використовуєте сторонні ресурси, але не відкриваєте їх для доступу Googlebot.
- Сайти на JavaScript мають свої складнощі. При використанні JavaScript сторінка може спочатку завантажитися з порожнім або неповним вмістом — це може призвести до певних проблем для Googlebot і інших пошукових систем під час спроби сканування та індексації контенту.
Етапи роботи Google-пошуку
Кожен етап в роботі пошукової системи надзвичайно важливий, і може бути для вас як перевагою серед конкурентів, так і суттєвою проблемою у ранжуванні сайту.
Намалювати коректну картину структури пошукової системи важко, але ми наведемо приклад роботи Маріо Фішера.
Ця схема побудована на основі витоку інформації, який стався у березні 2024 року під час антимонопольних слухань проти компанії Google. Витік виявив понад 14 000 потенційних функцій ранжирування, що практично вперше надає можливість справді зазирнути всередину системи пошуку Google.
Під час огляду, ми досить часто будемо звертатися до конкретних алгоритмів і модулів, тому пропонуємо одразу ознайомитися з відповідними патентами:
| Algorithm | Patent Number | Patent Link |
| DocIndex | US20080119159A1 | US20080119159A1 |
| SegIndexer | US20150175361A1 | US20150175361A1 |
| SimHash | US7657674B1 | US7657674B1 |
| PerDocData | US20080119159A1 | US20080119159A1 |
| Hitlist | US20090235859A1 | US20090235859A1 |
| Direct Index | US20080119159A1 | US20080119159A1 |
| Inverted Index | US6546237B1 | US6546237B1 |
| QBST | US20160244375A1 | US20160244375A1 |
| Term Weighting | US7032051B1 | US7032051B1 |
| Mustang | US20090014956A1 | US20090014956A1 |
| SiteChunk | US20090014956A1 | US20090014956A1 |
| ScanMin | US20080259677A1 | US20080259677A1 |
| GoldMine | US20090195317A1 | US20090195317A1 |
| RankBrain | US20150062652A1 | US20150062652A1 |
| DeepRank | US20160292055A1 | US20160292055A1 |
| QStar (NSR) | US20080259677A1 | US20080259677A1 |
| GWS | US7020970B1 | US7020970B1 |
| Tangram | US20110269188A1 | US20110269188A1 |
| InstantNavBoost | US20130143324A1 | US20130143324A1 |
| InstantGlue | US20130274445A1 | US20130274445A1 |
| FreshnessNode | US20070139203A1 | US20070139203A1 |
| Quality Rater | US20070083625A1 | US20070083625A1 |
| SnippetBrain | US20120174542A1 | US20120174542A1 |
| Superroot | US20090159259A1 | US20090159259A1 |
Збір та збереження даних у сховищах (Alexandria)
Розпочнемо з того, що всі проскановані сторінки переходять до наступного етапу — індексації та зберігаються в базі Alexandria.
Alexandria — це сховище, яке зберігає різні версії даних. Система індексування Google під назвою «Александрія» призначає унікальний DocID кожному вмісту.
Робота з базою даних працює за допомогою декількох алгоритмів:
- DocIndex відповідає за створення індексу документів, що дозволяє швидко знаходити потрібні файли в системі зберігання даних.
- SegIndexer відповідає за процес сегментації документів — розподіляємо їх на окремі частини або сегменти, які можуть бути індексовані та збережені окремо.
- SimHash — це метод для виявлення дублікатів. Алгоритм генерує хеш (спеціальний закодований номер) для кожного документа, що дозволяє порівнювати його з іншими файлами на наявність схожих або ідентичних частин.
- PerDocData — це система для зберігання даних для кожного документа з його специфічними метаданими, такими як інформація про автора, час створення, зміст, ключові слова тощо. Ця інформація та сигнали динамічно зберігаються в репозиторії ( PerDocData ).
Важливо: Google розрізняє URL-адресу та документ. Документ може складатися з кількох URL-адрес зі схожим вмістом, зокрема різними мовами, якщо вони належним чином позначені. Тут також сортуються URL-адреси з інших доменів. Усі сигнали з цих URL-адрес застосовуються через загальний DocID.
Коли кожному документу присвоюється власний ідентифікатор, водночас проходить процес оцінки слів, які виявлені на сторінці. Формується пошуковий індекс за релевантними ключовими фразами.
Саме на цьому етапі початково аналізується релевантність вашого контенту у документі:
- кількість входжень ключових слів;
- входження ключових фраз у метадані;
- формування заголовків;
- тощо.
У підсумку, для кожного ідентифікатора DocID присвоюється оцінка IR (information retrieval), яка є алгоритмічно обчислювана. Загалом ця оцінка і вирішує, чи буде ваша сторінка у першій десятці, чи взагалі сторінка буде ранжуватися за певною ключовою фразою.
А далі відбувається те, що може надовго викинути вашу сторінку з топу. І причина ховається в тому, що Google намагається економити свої ресурси. Він переміщує важливі документи в так званий HiveMind, тобто основну пам’ять і використовує як швидкі SSD, так і звичайні жорсткі диски (іменовані TeraGoogle) для тривалого зберігання інформації, яка не потребує швидкого доступу.
Дослідники зауважують, що посилання, включно зі зворотними посиланнями, які зберігаються в HiveMind, мають значно більшу вагу.
Багато систем звертаються до PerDocData пізніше, коли справа доходить до точного налаштування релевантності. Там зберігаються останні 20 версій документа (через CrawlerChangerateURLHistory).
Усе це наштовхує на логічні висновки:
- Аналіз контексту сторінки (документу) розпочинається з самого початку.
- Google може з легкістю вичислити ваші маніпуляції, зберігаючи до 20 останніх версій вашого документа.
Наприклад, існувала практика оновлення статей блогу лише через оновлення дати — вважалося, що це достатній сигнал для покращення ранжування. А насправді алгоритми системи пошуку використовують декілька перевірок: BylineDate (дата у вихідному коді), syntaticDate (витягнута дата з URL-адреси та/або заголовка) і semanticDate (взята з доступного для читання вмісту). І це дозволяє досить непогано визначити, чи справді контент було оновлено. Сюди додайте також порівняння з іншими 19 версіями документа і як результат — це сприяє пониженню рейтингу. - Збереження 20 копій документа наштовхує на думку, що часто для покращення ранжування недостатньо зміни якогось одного фактора. Якщо ви хочете повністю змінити вміст або тему документа, теоретично, вам потрібно створити 20 проміжних версій, щоб замінити старі сигнали вмісту.
Обробка в різних системах індексації
Коли сторінка потрапляє до сховища Alexandria, вона вже має унікальний ідентифікатор — DocID — і зберігається разом з усіма пов’язаними сигналами, метаданими та версіями контенту. Тому розглянемо детальніше, як відбувається процес пошуку потрібного документу з ідентифікатором (DocID) за відповідним запитом.
Після того, як документ зберігається в базі та отримує унікальний DocID, пошукова система має швидко знайти його серед мільярдів інших, коли хтось вводить запит. Для цього використовується кілька рівнів пошуку — від найшвидшого до найточнішого.
1. Hitlist — швидкий старт
Спочатку пошукова система звертається до так званого Hitlist — це список документів, які вже раніше були визначені як релевантні для певних запитів. Такий список дозволяє дуже швидко отримати результати, бо система просто «дістає» готові відповіді.
2. Direct Index — якщо потрібно точніше
Якщо Hitlist не дає достатньо релевантних результатів, підключається Direct Index — індекс, який напряму пов’язує слова з документами, в яких вони зустрічаються. Це вже глибший рівень аналізу, який дозволяє знайти нові або менш очевидні відповіді.
3. Inverted Index — найпотужніший інструмент
Для ще складніших запитів використовується Inverted Index. Замість того, щоб зберігати документи з їх вмістом, він зберігає слова з прив’язкою до всіх документів, де вони є. Тому Inverted Index добре підходить для складних запитів та дозволяє економити ресурси, оскільки працює з меншим обсягом даних.
| Hitlist | Швидкий доступ до «важливих» сторінок.Пришвидшення відповіді на пошукові запити. |
| Direct Index | Прямий індекс як засіб зменшення часу доступу. |
| Inverted Index (wordindex) | Механізм зворотного індексу: пошук за ключовими словами.Важливість для ефективного зіставлення запит–контент. |
Це ще раз підтверджує гіпотезу, що при формуванні контенту, важливо не лише додавати ключові фрази, а й формувати певну структуру тексту та відповідати запиту користувача.
Аналіз запиту
Коли користувач вводить пошуковий запит, підключаються алгоритми, які
- оцінюють та аналізують запит для розуміння контексту;
- QBST оцінює релевантність — наскільки документи відповідають запиту користувача;
- звужують терміни для точного ранжування.
QBST (Query-based Scoring Tool) — це внутрішній інструмент Google, який оцінює релевантність документів стосовно пошукового запиту. Його мета обрати найбільш релевантний документ. Процес зважування термінів досить складний і включає такі системи, як RankBrain, DeepRank (раніше BERT) і RankEmbeddedBERT.
Розглянемо детальніше, що саме роблять алгоритми та чим відрізняється їх робота на різних етапах.
| Алгоритм | Основна функція | Особливість |
| Term Weighting | Визначення важливості термінів | Обчислює, які слова в запиті або документі є ключовими для релевантності |
| RankBrain | Векторизація запитів | Обробляє нові/незрозумілі запити |
| DeepRank (BERT) | Розуміння контексту | Оцінює відповідність сторінки запиту |
| RankEmbeddedBERT | Векторна семантика | Глибока релевантність на основі сенсу |
«Банальне» використання ключових фраз у тексті вже є недостатнім для оцінки вашого контенту не лише як корисного, а й релевантного до поставленого запиту користувачем. Це стає зрозумілим зі складності оцінки алгоритмами, залучення штучного інтелекту та направленість на визначення прихованого наміру користувача.
Ще один елемент для аналізу, який Google використовує у роботі із запитами, це Knowledge Graph.
Якщо говорити простою мовою — це умовний словник, де запити пов’язуються зі справжніми сутностями, а не просто словами. Схематично це виглядає так:
Після оцінки запиту, він передається у систему оцінки рейтингу Mustang, де розпочинається процес підбору релевантних документів.
Модулі ранжування
Це етап, коли пошукова система вже знає, які сторінки можуть відповідати на запит, і тепер вона вирішує: які з них найкращі? І в якому порядку їх показувати?
Запит передається Ascorer для подальшої обробки — він отримує 1000 найпопулярніших DocID для заданого запиту (ключової фрази) з Inverted Index, упорядкованого за IR-балом. Згідно з внутрішніми документами, цей список іменується «зеленим кільцем».
Далі в системі модуля Mustang відбувається фільтрація результатів для точнішого відбору сторінок:
- Видаляються дублі: якщо кілька сторінок мають майже однаковий вміст, за допомогою алгоритму SimHash визначається найоригінальніша.
- Аналізуються уривки: модуль перевіряє, наскільки добре фрагменти сторінки (наприклад, заголовки чи перші абзаци) підходять до запиту.
- Відбувається пошук оригінальний і корисний контенту: система віддає перевагу сторінкам з унікальною та цінною інформацією, а не просто зібраним з інтернету текстом.
Цей результат досягається завдяки тому, що система Mustang об’єднує моделі для створення єдиної логіки пошуку: визначає, які підмоделі та сигнали активувати для кожного запиту. Можна сказати, це «диригент» пошукового процесу. Під час її роботи використовуються такі «низькорівневі» алгоритми: ScanMin (ScaNN), SiteChunk, GoldMine, QStar, PageRank.
- ScanMin (ScaNN) — алгоритм векторного пошуку, який дозволяє швидко знаходити найбільш схожі документи за векторною близькістю.
- SiteChunk — розбиває сайт або сторінку на логічні «частини» (chunks), щоб краще аналізувати контент і покращити розуміння структури документа.
- GoldMine — внутрішній інструмент, який відповідає за витягування структурованих даних з неструктурованого тексту.
- QStar (NSR — Neural Semantic Retrieval) використовує глибоке семантичне розуміння запиту й документа для нейронного ранжування результатів, працює на базі векторних представлень.
- PageRank — класична основа ранжування на основі авторитетності.
За уточнення результатів відповідає система Superroot, яка дає змогу провести переранжування, виконуючи точну роботу зі скорочення «зеленого кільця» (1000 DocID) до «синього кільця» лише з 10 результатами.
Важливою частиною системи Superroot є модуль Navboost. Він відповідає за те, щоб Google міг легко оцінити пошукову поведінку, включно з пошуком, кліками, повторними пошуками та кліками — безпосередньо в результатах пошуку. Поговоримо про модуль Navboost трохи згодом.
Формування видачі
Настав час сформувати результати видачі для користувача. Для цього GWS, який отримує результати з попередніх модулів обробки запиту, збирає остаточну сторінку для користувача.
GWS (Google Web Server) — це сервер, який відповідає за обробку фінального запиту користувача та вивід результатів пошуку в браузері.
Разом з цим ще 2 модулі працюють паралельно, для формування кінцевого результату SERP:
- Tangram — це шаблонний та логічний модуль, який відповідає за структурування SERP. За задумом він динамічно адаптує блоки, щоб SERP був найбільш корисним.
- Glue — це модуль, який інтегрує всі типи результатів. Завдяки Glue результат «оживає»: він має фавікон, зірочки рейтингу, ціни, навігацію — все, що виводиться у SERP поза звичайним посиланням.
Сигнали реального часу
Коли здається, що вже всі етапи пройдено, усі аналізи зроблено, а висновки отримано — Google продовжує доопрацьовувати свою видачу. Навіть коли система Superroot сформувала результат у вигляді «синього кільця» (10 документів), Google продовжує відслідковувати, як користувач реагує на отриманий результат. Розглянемо детальніше, які алгоритми це роблять:
- FreshnessNode — модуль, що оцінює актуальність документа або сторінки в момент запиту.
- InstantNavBoost — модуль, що слідкує за тим, чи «задоволений» користувач результатом, чи знову повертається у видачу. InstantNavBoost враховується в мікроранжуванні — може змінити позицію документа в конкретній сесії чи для подібних запитів.
- InstantGlue — доповнення до модуля Glue, яке в реальному часі змінює структуру SERP, залежно від запиту та контексту.
Тому видача може змінюватися буквально в реальному часі, залежно від попиту, поведінки та контексту. І найпевніше саме ця частина найбільше впливає на те, як ранжується новий контент та втрачає свої позиції застарілий.
Тестування
Водночас з тим, як користувачу віддається результат з системи Mustang, чи оновлений результат після Superroot, відбувається процес тестування.
Для цього Google використовує Twiddler — платформу для експериментів і «тонкого підкручування» результатів, яка дозволяє запускати A/B тести в SERP у реальному часі. Різні документи вказують на те, що використовується кілька сотень систем Twiddler.
Ви не можете вплинути на те, як Twiddler змінює порядок ваших результатів, але розуміння його механізмів може допомогти вам інтерпретувати коливання рейтингу або «незрозумілі рейтинги». Важливо регулярно переглядати SERP і зазначати типи результатів.
Система Twiddlers формує варіанти видачі для тестування, а додатковий модуль IS4@5 проводить розгортання на інфраструктуру ранжування в реальному часі, забезпечуючи швидке тестування даних варіантів.
Google формує результати пошуку на основі тисяч сигналів. Через постійні тести у SearchLab та систему Twiddler навіть зворотні посилання можуть втратити вагу. Тобто, якщо змінюється поведінка користувачів — ваш сайт може втратити позиції, навіть якщо ви нічого не змінювали.
Оцінка якості (Quality Rater)
Для того, щоб кожен модуль та система працювали успішно, Google постійно оцінює їх результати та «тренує» свою автоматичну систему оцінки. Для цього компанія використовує кілька тисяч оцінювачів якості по всьому світу і заявляє, що їхні оцінки безпосередньо не впливають на рейтинг.
Як працює система оцінювання якості сторінок (Quality Rater):
- Спеціальні оцінювачі перевіряють сайти та відповідають на запитання, які допомагають оцінити якість контенту.
- Їхні відповіді використовуються для навчання алгоритмів — щоб система розуміла, чим хороший сайт відрізняється від поганого.
- Частині перевірених сторінок присвоюється оцінка IS (Information Satisfaction) — наскільки добре сторінка відповідає на запит. Цю оцінку потім поширюють на схожі сторінки — щоб автоматично ранжувати їх без ручної перевірки.
- Якщо система не може знайти схожі сторінки, вона знову звертається до оцінювачів.
- Що більше оцінювачі перевіряють вручну, тим більше сайтів надалі система може оцінювати сама.
З суттєвим покращенням моделей машинного навчання, найпевніше, роль оцінювачів буде змінюватися, але оцінка живого користувача все ще залишатиметься важливою. Тому час згадати інструкцію для асесорів, відповідно до якої, оцінювачі й проводять аналіз сторінок. Чим краще ви розумієте критерії — тим ближче ви до топових позицій.
Висновок
Ваш сайт може зіткнутися з проблемами як на етапі виявлення сайту пошуковою системою, так і на етапі його оцінки та подальшого ранжування. Адже Google використовує для своєї екосистеми складний підхід, який постійно еволюціонує.
Краще розуміння алгоритмів та процесів, які відбуваються під час оцінювання вашого сайту, дозволяє будувати більш життєздатні гіпотези щодо необхідних впроваджень.
Автор: Олександр Ковальчук, SEO-спеціаліст Promodo